2018/6/28 大津
7-0 なぜアルゴリズムとデータ構造を学ぶのか
アルゴリズムとは?
目的の結果を得るための手順のこと
データ構造とは?
データを効率よく処理するための配置方法のこと
なぜ学ぶのか?
プログラムの設計段階で、アルゴリズムとデータ構造を明確にしておく必要があります。
どんなプログラムでも、分解していけば単純なアルゴリズムです。
→基本を身につけて応用していきましょう!
アルゴリズムを考えるコツ
1 処理の区切りを見つける
2 処理をコツコツと進める
3 データの値の変化をトレースする
この章ではいくつかアルゴリズムを学びますが、
この3つのコツを踏まえていれば難しくありません!がんばりましょう!
≪本章の内容≫
1 基本的なアルゴリズム
2 基本的なデータ構造
3 疑似言語の表記方法
7-1 基本的なアルゴリズム
FE試験で出題される基本的なアルゴリズムは、ソート(整列)とサーチ(探索)に分類できます。2つとも配列を対象としたアルゴリズムです。
それぞれ見ていきましょう。
ソート(整列)
ソートとは?
配列の要素の順序をそろえること(小さい順=昇順 大きい順=降順)。
バブルソート、選択ソート、挿入ソート、マージソート、クイックソートなどがあります。
実際にやってみましょう
≪前提条件≫
・配列の要素:整数(1、2,3,4)
・スタートの状態:4312 の順で並んでいる
・目標:昇順に並べる。
バブルソート ―データを交換する―
アルゴリズム:
「配列の先頭または末尾から、隣同士の要素を比較し、
小さい方が前になるように交換する。」
※通常は末尾から先頭へ向かって処理することが多いらしいです。
下図でもそのようにしています。
(小さい要素が泡のように浮かび上がってくるので、バブルソートといいます)

選択ソート ―データを選択する―
アルゴリズム:
「配列の先頭から末尾に向かって要素の値をチェックし、
最小値を選択して、それを先頭の要素と交換する。」

挿入ソート ―データを挿入する―
アルゴリズム:
「配列の先頭から末尾に向かって、要素を1つずつ取り出し、
それより前の部分の適切な位置に挿入する」
※「先頭の要素は既に先頭に挿入されている」として始めます。

マージソート ―データを結合する―
「要素数が1になるまで配列を2分割し、分割した配列から要素を小さい順に取り出して、結合する」
やってみましょう。

もっとデータ量が多い場合はどうなるか、
興味のある方は調べてみてください。
クイックソート ―データをグループ分けする―
アルゴリズム:
「配列の中から基準値を1つ選び、
残りの要素を、基準値との大小でグループ分けする」
※ここでは、説明をしやすくするために
配列に含まれているデータを1から7の整数とします。

サーチ(探索)
サーチとは?
配列の中から目的のデータを見つけること。
一般的に、サーチの結果となるのはデータの位置(=配列の要素番号)です
※データの内容ではありません
データが見つからない場合は、要素としてあり得ない位置を結果とします
EX) 配列の先頭が0番 → 結果は-1
サーチ1:二分探索法
「真ん中の数をチェックする」ことを繰り返して数を当てます。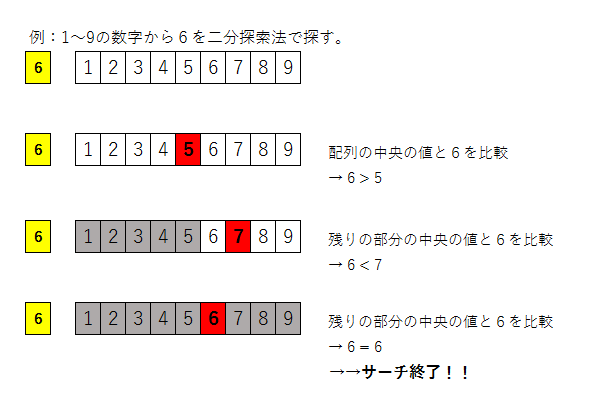
※二分探索法はデータがソート済みでなければ使えません。
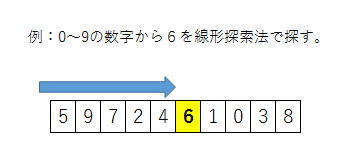
サーチ2:線形探索法
(配列がソートされていなくても使用OK)
先頭から順番にチェックする方法です。
ソートしなくても使えますが、この方法は処理回数が多くなりがちなので、効率的ではありません。
サーチ3:ハッシュ表探索法
ハッシュ表探索法では、データの値と格納場所を対応づけることで、
データ数に関わらず一発で目的のデータを見つけることができます。
データの値と格納場所を対応付けるためには、
あらかじめ用意しておいた計算(ハッシュ関数)を行います。
ここで得られた計算結果(ハッシュ値)を利用して、データの格納場所を定めます。(データの格納場所となる配列をハッシュ表と呼びます)
イメージはこんな感じです。
ただし、注意してほしいのが
ハッシュ表探索法において目的のデータを一発で得られるのは、理想的な状況だけということです。
「理想的な状況」とは、「同じ場所に格納するデータが生じる確率が無視できるほど小さいとき」を指します。
実際に使うときは、重複が生じないようにハッシュ関数を考えてみてください。
アルゴリズムの効率を考えよう
効率を明確に示す手段として、計算量(order)があります。
計算量とは、N個のデータを処理して目的の結果を得るまでの最大の処理回数です。(いくつか定義があります)
オーダの頭文字Oを用いて、O(数式)で表します。この表記方法をオーダ記法といいます。
基本的なソートとサーチのアルゴリズムの計算量は下表のとおりです。
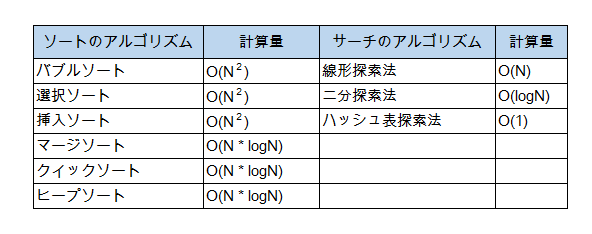
※注意!!
上記の表、これまでに挙げたアルゴリズムの計算量とは一致していません。
例えば、先にあげた例では、バブルソートの計算量を数えると6になるはずです。
このデータ量なら、計算量はn(n-1)/2 です。
なぜ違うのか?
オーダ記法ではデータ量がものすごく多いことを想定しているので、
以下のルールに従って計算量を出しています。
ルール1:影響の1番大きな項(最大次数の項)だけ残す
例:n(n – 1)/ 2 = (n² – n )/2 なので n² / 2 だけ残します。
ルール2:定数倍の違いは無視する
例:n² / 2 をn²にします。
わからない人はぐぐってみてください。
7-2 基本的なデータ構造
データ構造にはリスト、二分探索木、ヒープ、キュー、スタック、などがあります。
が、基本は配列です。
それぞれのデータ構造は、配列の使い方を工夫することで実現されています。
パターン1:リスト構造
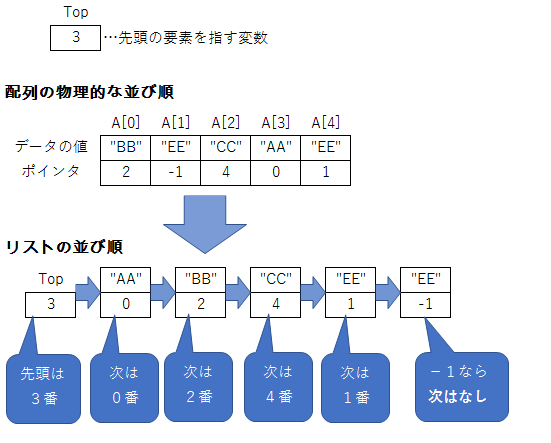
リスト=配列の1つの要素に、2つの情報を持たせたもの。
1つめ:データの値
2つめ:次にどの要素とつながるか(この情報をポインタを言います)
下にリストの例を示します。
リストには、本体である配列と、リストの先頭の要素を指す変数が必要です。
【長所】
通常の配列より、要素の挿入・削除が効率的に行える(ポインタを書き換えるだけ)
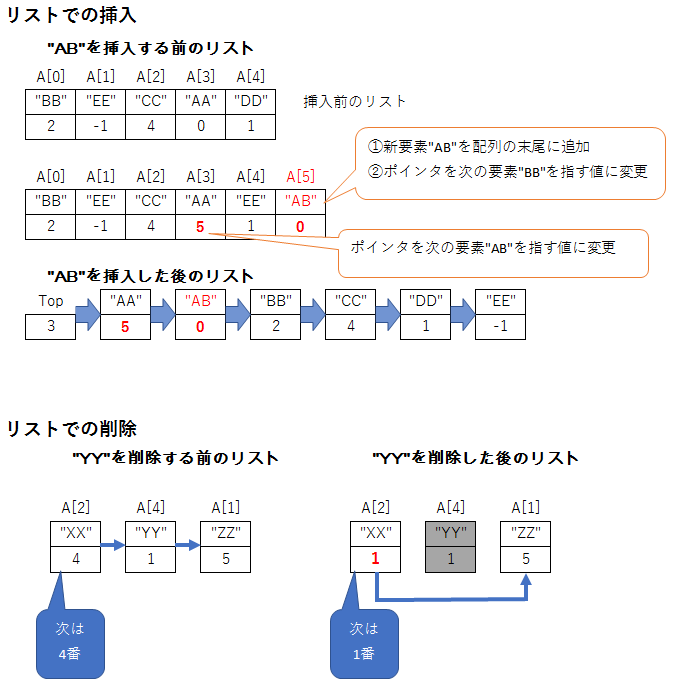
【短所】
通常の配列と比べて、要素の読み書き処理が遅い(ポインタをたどる必要があるから)
【リストの種類】
短方向リスト:前から後ろだけに辿れる
双方向リスト:前から後ろ、後ろから前の両方向から辿れる
環状リスト:末尾と先頭の要素がつながっている

パターン2:木構造 二分木(binary tree)
リストの1つの要素に2つのポインタをもたせて、1つの要素から2つの要素に辿れるようにしたデータ構造を二分木と呼びます。
基本情報技術者試験で取り上げられる二分木は、二分探索木とヒープの2つです。
二分探索木とは?
左に小さいデータ、右に大きいデータをつなぐ二分木です。
データを探索するために使います。
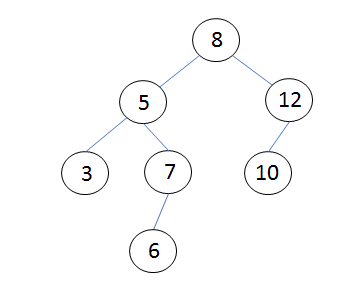
二分探索木は、下図のように根、節、葉、枝の4つの構成要素からできています。
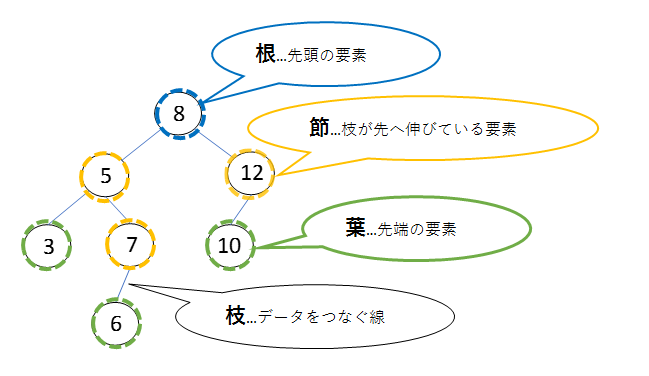
二分探索木を作ってみよう
FE試験では二分探索木を構築しろという問題が出ることがあるので、
手順を確認しておきましょう。
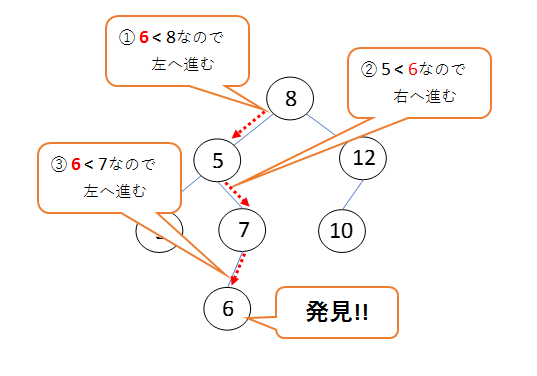
二分探索木を構築するときはまず、配列の最初の要素を根とします。
それ以降のデータは、根からスタートして、木の先の適切な位置につないでいきます。
実際に構築してみましょう。
空の二分探索木の8, 12, 5, 3, 10, 7, 6の順にデータを与えるとすると、
以下の手順で構築することになります。

ヒープ(heap)とは?
ヒープとは、直訳すると「堆積物」という意味です。
データの配置方法が堆積物に似ているので、こう呼ばれます。
二分探索木は探索のために使用されるのに対して、
ヒープはデータをソートするために使われます。
下図のように、大きなデータの上に小さなデータが積み重なったデータ構造です。

ヒープを使うとデータをソートできます。(ヒープソート)
「根を取り出し、残ったデータをヒープに再構築する」ことを繰り返して、取り出した「根」を並べていけばデータを昇順にソートできます。
パターン3:バッファ
すぐに処理しないデータを一時的に格納しておくための配列をバッファと呼びます。バッファの種類には「キュー」と「スタック」があります。
キュー(FIFO:First In First Out形式のバッファ)
キューにデータを格納すること = エンキュー(enqueue)
キューからデータを取り出すこと = デキュー(dequeue)
先に格納したものから取り出します。
スタック(LIFO:Last In First Out形式のバッファ)
スタックにデータを格納すること = プッシュ(push)
スタックからデータを取り出すこと = ポップ(pop)
最後に格納したものが最初に取り出されます。

イメージはつかめましたか?
それでは、キューとスタックの操作を例題で見てみましょう!

実際にノートに書きながら例題を解いてみてください。
解説は下にあります。例題がとけたらスクロールしてみてください。
・
・
・
・
・
・
できましたか?処理をひとつずつ追いかけると下図のようになります。
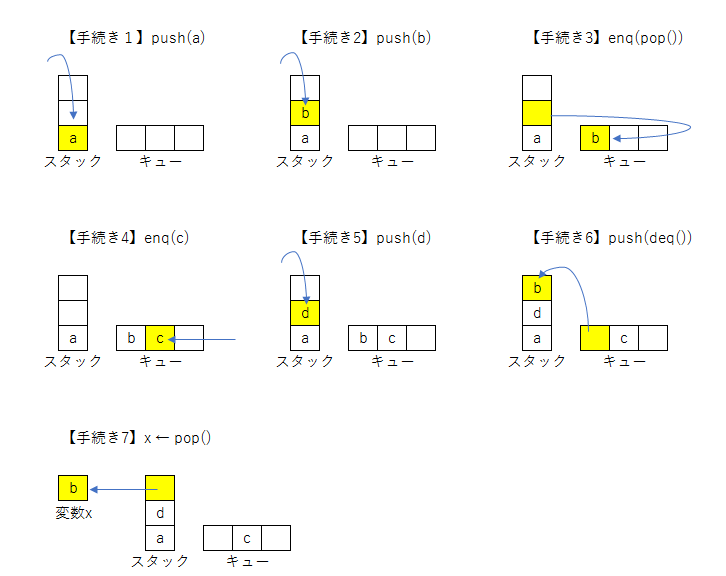
ということで、答えは選択肢イ(b)です。
7-3 疑似言語の表記方法
疑似言語とは?
架空のプログラミング言語です。
データの入れ物を変数で表し、処理のまとまりを関数で表します。
(関数は、手続、副プログラムとか呼ばれることもあります。)
記述方法は下表のとおりです。

例えばこんな処理が書けます。

変数AnsはAverage関数の中でのみ使用されます。
このような変数をローカル変数や局所的変数といいます。
関数の外側で宣言された変数は、グローバル変数や大域的変数と呼ばれ、プログラムのすべての部分から使用できます。
基本の処理・・・順次、分岐、繰り返し
1 順次
上から順番に実行する、という処理です。
プログラムは基本的に上から下へ進むので、特別な表記がなければすべて順次処理、と思ってください。
2 分岐
分岐には2種類あります。
・単岐選択処理:「条件式が真なら処理を実行せよ」(if文)
・双岐選択処理:「条件式が真なら処理1を、偽なら処理2を実行せよ」(if else文)
という処理です。
3 繰り返し
ある条件式が真である限り、指定の処理を繰り返します。
条件式を判定してから処理を行う前判定と
処理を行ってから条件式を判定する後判定があります。
前判定はwhile文、後判定はdo while文のイメージです。
繰り返し応用編:多重ループ
繰り返しの中に繰り返しを入れる、入れ子構造を作ります。
以下のように表記します。

繰り返し応用編2:再帰呼出しによる繰り返し
再帰呼出し(recursive call)とは?
関数の処理中で同じ関数を呼び出すことによって、繰り返しを行うテクニックです。
whileやfor文よりも短く、効率よく書きたいときに使います。
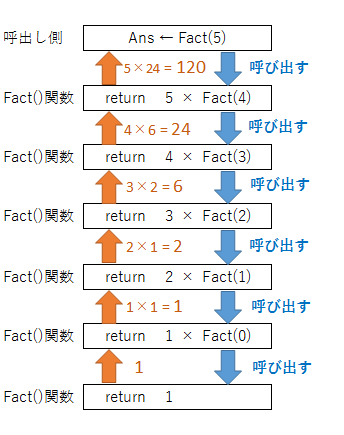
例として、引数Nの階乗を求める関数を見てみましょう。

2行目:N = 0がtrueのときは1を戻り値として返します。
(数学で0の階乗は1と決められているからです。)
4行目:N = 0でない場合、戻り値としてN × Fact( N – 1 )を返します。
例えばN = 5の場合は、5の階乗を、5×(4の階乗) で求めることになります。
4の階乗を4×(3の階乗)で、
3の階乗を3×(2の階乗)で、
2の階乗を2×(1の階乗)で、
1の階乗を1×(0の階乗)で求めます。
下図で追いかけてみましょう。